
Critical Threat Intelligence & Advisory Summaries
The Breach Nobody Saw Coming: When AI Becomes the Attack Vector
Timur Mehmet
AI breaches aren’t coming through firewalls anymore—they’re happening through conversations. While organizations celebrate productivity gains, sensitive data is leaking through tools no one is tracking or governing. This isn’t a future risk—it’s already happening.
Organizations deploy AI, celebrate the efficiency gains, then get blindsided by vulnerabilities they never knew existed. The same pattern has been observed unfolding across dozens of organizations.
The UK's National Cyber Security Centre warned us about an "emergent class of vulnerability" in AI systems. That phrase sounds like technical jargon, but it describes something far more dangerous: attacks that literally emerge from how AI systems learn and respond.
The breach doesn't come through the door. It comes through the conversation.
The Invisible Inventory Problem
A critical observation emerges: organizations aren't thinking about AI in terms of asset management.
They don't know what they've deployed. They can't tell you which large language models are running in production. They have no inventory of the algorithms making decisions across their operations.
Without that inventory, organizations cannot address vulnerabilities or prevent harm to users and consumers of AI-based services.
The numbers tell the story. An analysis of 22.4 million prompts across six generative AI applications in 2025 found that 579,000 prompts contained company-sensitive data. That's 2.6% of all interactions leaking information.
Code exposure led the way at 30%, followed by legal discourse at 22.3%, merger and acquisition data at 12.6%, financial projections at 7.8%, and investment portfolio data at 5.5%.
Perhaps most concerning: 17% of all exposures involved personal or free accounts where organizations have zero visibility, no audit trails, and data may train public models.
The Workflow Became the Weapon
Traditional security approaches fail here because the attack surface has fundamentally changed.
Anyone with internet access can sign up for a free AI service using federated logins like Google or Apple. They start using the service immediately. This bypasses the onboarding process entirely, which means there's no governance.
It's difficult to spot using web browsing technologies because these AI services could be anywhere, integrated into all sorts of services.
Cases have been documented where audit reports were put into generative AI to rewrite and then issued to clients. The result? Reports riddled with issues and a breach of confidentiality.
The breach happened through the workflow itself, not through a hack.
Of those 22.4 million prompts analyzed, data exposures most commonly involved ChatGPT at 71%. Google Gemini accounted for 6%, Microsoft Copilot for 3.5%, Claude for 2.5%, and Perplexity for 1.3%.
Research from Concentric AI found that GenAI tools such as Microsoft Copilot exposed approximately three million sensitive records per organization during the first half of 2025.
This mass exposure occurs because AI systems access data across organizational boundaries without the traditional access controls that would limit human users.
It's Already Happening
Many may assume the first major "AI-convinced breach" is a future threat.
It's not.
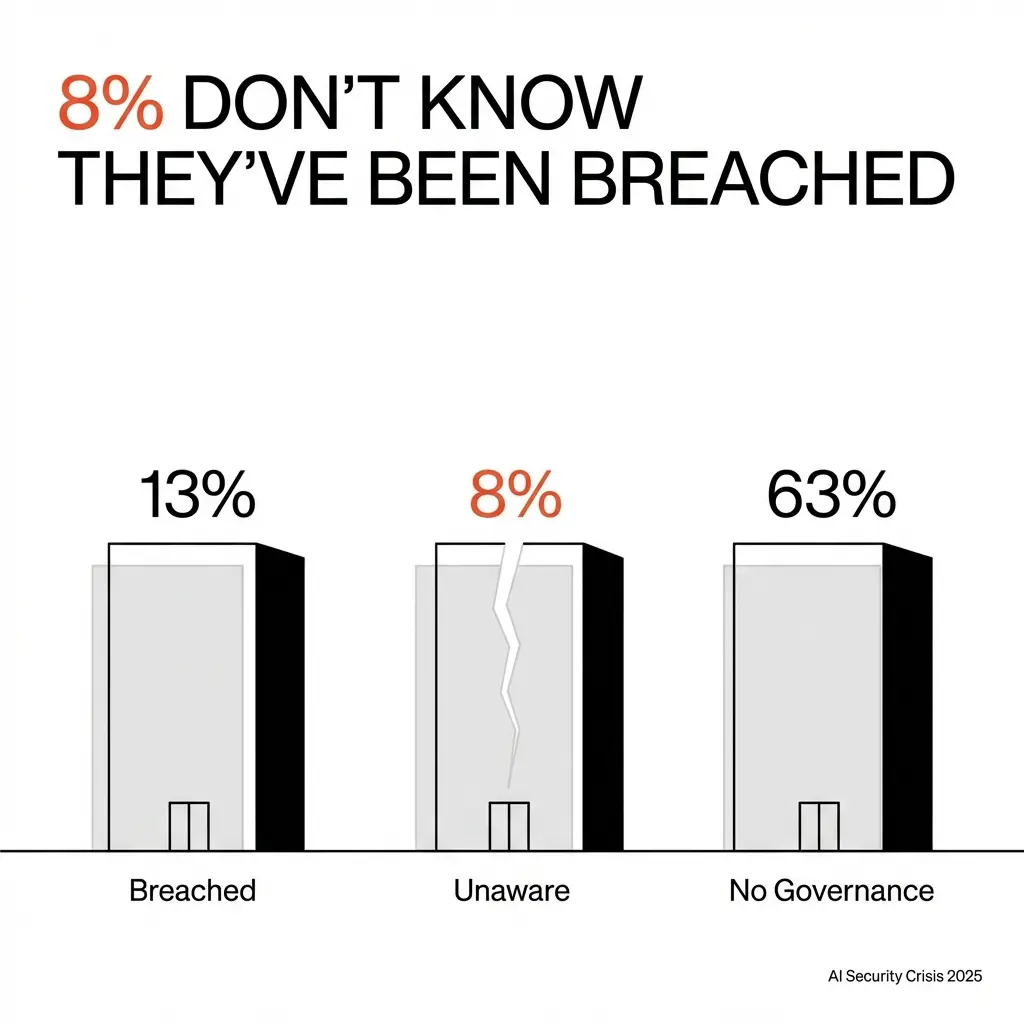
The IBM 2025 AI breach report revealed that 13% of surveyed organizations reported breaches of AI models and applications. Another 8% were unaware if they had been compromised.
Read that again: 8% don't even know they've been breached.
No fewer than 63% of the breached organizations had no governance policy in place.
Industry professionals in various outsourcing suppliers in Europe and the US who deployed AI to improve their processes are reporting privately that attackers are already targeting multi-agent systems. The attackers go after the less protected AI agents to compromise the results presented or decisions being made.
In March 2025, a Fortune 500 financial services firm discovered its customer service AI agent had been leaking sensitive account data for weeks through a carefully crafted prompt injection attack. The attack bypassed every traditional security control.
The incident cost millions in regulatory fines and remediation.
The Architecture Problem We Can't Patch
What makes this different from traditional security challenges is fundamental.
The UK's National Cyber Security Centre warns that prompt injection attacks against LLM systems "may never be totally mitigated in the way SQL injection attacks can be."
The agency describes LLMs as "inherently confusable" because they cannot reliably distinguish between developer instructions and user input.
Unlike traditional code vulnerabilities that you can patch, this is a fundamental architectural limitation of how AI processes language.
Academic research demonstrates that just five carefully crafted documents can manipulate AI responses 90% of the time through Retrieval-Augmented Generation poisoning. Attackers can compromise AI systems not by breaking through defenses, but by poisoning the content that AI systems naturally ingest and process during normal operations.
The OWASP Top 10 for LLM Applications 2025 maintains Prompt Injection as the primary threat. OWASP acknowledges the fundamental limitation: "LLMs cannot reliably separate instructions from data, with inputs affecting models even if imperceptible to humans."
53% of companies now rely on RAG and agentic pipelines, massively expanding the attack surface.
The Scale of What's Coming
Lakera AI researchers documented over 91,000 attack sessions targeting AI infrastructure and LLM deployments during a 30-day period in Q4 2025.
The data reveals that "indirect attacks targeting features like browsing, document access, and tool calls succeed with fewer attempts and broader impact than direct prompt injections."
Attackers are already exploiting agentic capabilities as they emerge.
The NCSC's 2025 Annual Review documented an alarming 50% year-over-year increase in "highly significant" incidents for the third consecutive year. That's a dramatic escalation from just 89 nationally significant incidents in the prior year to 204 in the reporting period.
The artificial intelligence prompt security market is witnessing explosive growth, escalating from $1.51 billion in 2024 to a projected $5.87 billion by 2029, with a compound annual growth rate of 31.2%.
This rapid expansion is driven by enterprise deployment of chat assistants, increased data privacy compliance requirements, and the recognition that conversational AI creates fundamentally new attack surfaces.
Shadow AI Makes Everything Worse
Shadow AI breaches cost an average of $670,000 more than traditional security incidents and affect roughly one in five organizations.
These tools operate outside company supervision, allowing sensitive data to slip into public platforms unnoticed. They create invisible attack surfaces that security teams never approved or monitored.
In November 2025, researchers documented the first widely reported AI-orchestrated cyber espionage campaign where threat actors used Claude AI to automate most operational steps of their attacks. Chinese spies leveraged the AI system to break into critical organizations.
That marked a watershed moment where offensive operations moved into semi-autonomous execution against critical infrastructure.
What This Means for You
The single most dangerous misunderstanding currently observed: security teams believe they can protect AI systems using traditional approaches.
They cannot.
The foundation begins with asset management. If organizations don't know what they have, where they've deployed it, what its purpose is, and who is responsible for it, it's difficult for those deploying AI models to say with confidence they're in control when it comes to vulnerabilities.
Organizations need to understand what they have deployed as an asset. That means LLMs, algorithms, multi-agent systems, and every integration point where AI touches organizational data.
Organizations need to understand what harms these systems could cause. That could be anything from the AI being used to launch an intelligent attack across any type of channel or vector, to compromises of AI itself such as giving bad or dangerous advice or making incorrect decisions, to vulnerabilities in the AI tech stack itself due to lack of inventory and understanding of what is deployed.
Without that foundation, organizations are building security on sand.
The breach organizations cannot see is already happening. The question is whether they will discover it through their own monitoring or through a regulatory fine, a customer notification, or a headline.
Start Here
Addressing this threat requires three immediate actions:
1. Complete your AI asset inventory
Document every AI system, model, and integration in production. Include ownership, purpose, data access, and update frequency.
2. Map your exposure surfaces
Identify where AI systems interact with sensitive data, make decisions, or communicate with users. These are your new attack vectors
3. Establish AI governance before deployment
No AI system goes live without documented controls, monitoring capabilities, and incident response procedures.
The organizations that survive the next wave of AI-based attacks won't be the ones with the best firewalls.
They'll be the ones who understand that the conversation itself has become the vulnerability.
Author: Hackerstorm.com
References:
UK National Cyber Security Centre – AI & Prompt Injection
-
TechRadar report on NCSC warning that prompt injection attacks might never be fully mitigated — prompt-level vulnerabilities are structural in LLMs, unlike traditional exploits. Prompt injection attacks might 'never be properly mitigated' UK NCSC warns
OWASP Top 10 for LLM Applications 2025
-
Official OWASP documentation of the Top 10 LLM risks showing Prompt Injection as the top-ranked threat. OWASP Top 10 for LLM Applications 2025 (PDF)
-
OWASP’s explanation of the Prompt Injection category (LLM01) itself. LLM01:2025 Prompt Injection – OWASP Gen AI Security Project
AI Security & Risk Research
(These relate to the kinds of studies referenced in your text about prompt injection and leaks — though not always the exact numbers your article cites, they cover the same themes of sensitive data exposure and prompt-level security risks.)
-
Comprehensive review of prompt injection attacks and LLM vulnerabilities. Prompt Injection Attacks in Large Language Models and AI Agent Systems: A Comprehensive Review
-
Academic case study on zero-click prompt injection in a production LLM system. EchoLeak: The First Real‑World Zero‑Click Prompt Injection Exploit in a Production LLM System (ArXiv)
IBM 2025 Data Breach & AI Security Findings
-
IBM report noting that 13% of organizations reported breaches involving AI models or applications, with most lacking proper AI access controls. IBM Report: 13% Of Organizations Reported Breaches Of AI Models Or Applications
Concentric AI & Data Exposure Insights
-
Concentric AI report highlights generative AI data risk exposure, including Copilot accessing millions of sensitive records per organization. GenAI is exposing sensitive data at scale – Concentric AI findings
Enterprise Prompt Leak Statistics
-
Cybernews coverage of enterprise AI prompts exposing sensitive data (based on 22M+ prompt data set). 1 in 25 enterprise AI prompts sent to China‑based tools (Harmonic data)